1. About
About SecHub
SecHub stands for "Security Hub" and serves as an unified API to scan for various security issues. With SecHub, users don’t need to worry about the specific scanning product used on the server side; they simply configure their desired security goals.
|
The SecHub server alone does NOT provide a security infrastructure but orchestrates different security products/tools. Please check our ready to use security open source tools: PDS solutions for integration with SecHub server. |
It was designed to be very easy to integrate into existing build / contionus integration (CI) pipelines and helps to provide SecDevOps.
|
You can get more documentation from the SecHub web page . The project is hosted at https://github.com/mercedes-benz/sechub |
About documentation
This documentation is part of SecHub.
| Key | Value | Information |
|---|---|---|
LICENSE |
MIT License |
Please look at https://github.com/mercedes-benz/sechub/blob/master/LICENSE |
Documentation version: PDS 2.4.0 modified (commit 00b7777) - Build date: 2025-09-01 14:49 (UTCZ)
About PDS (Product Delegation Server)
The product delegation server (PDS) represents a server which is highly configurable and
can execute any command line tool. It has no runtime dependencies to SecHub, so it can be used
independently.
Via PDS it is possible to easily integrate new security products into SecHub without writing
adapters or executors, because PDS is automatically supported as it is a part of the SecHub ecosystem.
You can use PDS instances also highly available in a clustered way - e.g. by using Kubernetes.
See Operating the SecHub PDS
2. Download
A ready to use executable .jar binary of PDS (Product Delegation Server)
is available at GitHub.
Download link to the latest SecHub PDS release: https://mercedes-benz.github.io/sechub/latest/pds-download.html For documentation, please look at SecHub web page .
3. Concept
3.1. Product delegation server
3.1.1. General
3.1.1.1. PDS In an nutshell
There are many open source clients available having no server component inside so lacking:
-
REST access
-
queuing
-
status requests
-
scalable
-
… more
So when we want to adapt them in SecHub style (the product does the work and we ask for result) we
need to provide a ProductDelegationServer (in short form PDS).
PDS is
-
a spring boot application which uses a network DB for providing cluster possibility
-
a complete standalone application without runtime dependencies to SecHub server (or its shared kernel)
-
provides REST access
-
a very simple priviledge model with just two users (
tech user+admin user), basic auth viaTLS, credentials are simply defined by environment entries on startup -
provides jobs, queing, monitoring etc.
-
can execute single files (e.g. a bash script), where job parameters are available as environment variables at runtime
-
a standard way to integrate any product into SecHub in a scalable and easy way
3.1.1.2. Handling of resources
-
PDS server provides
auto unzippingof uploaded resources when configured - see PDS server configuration file -
When a PDS job fails or is done the resources inside job workspace location are automatically removed
3.1.1.3. Communication between SecHub and PDS
The communication between SecHub server and PDS is very similar to the communication between SecHub client and SecHub server.
The PDS adapter will do following steps from SecHub side - as a client of PDS:
-
creates a PDS job
-
(Optional: Only necessary when PDS does not resuse SecHub storage) uploads sources and/or binaries to PDS
-
approves PDS job
-
waits until PDS job has finished
-
downloads PDS report data
As shown in next figure:
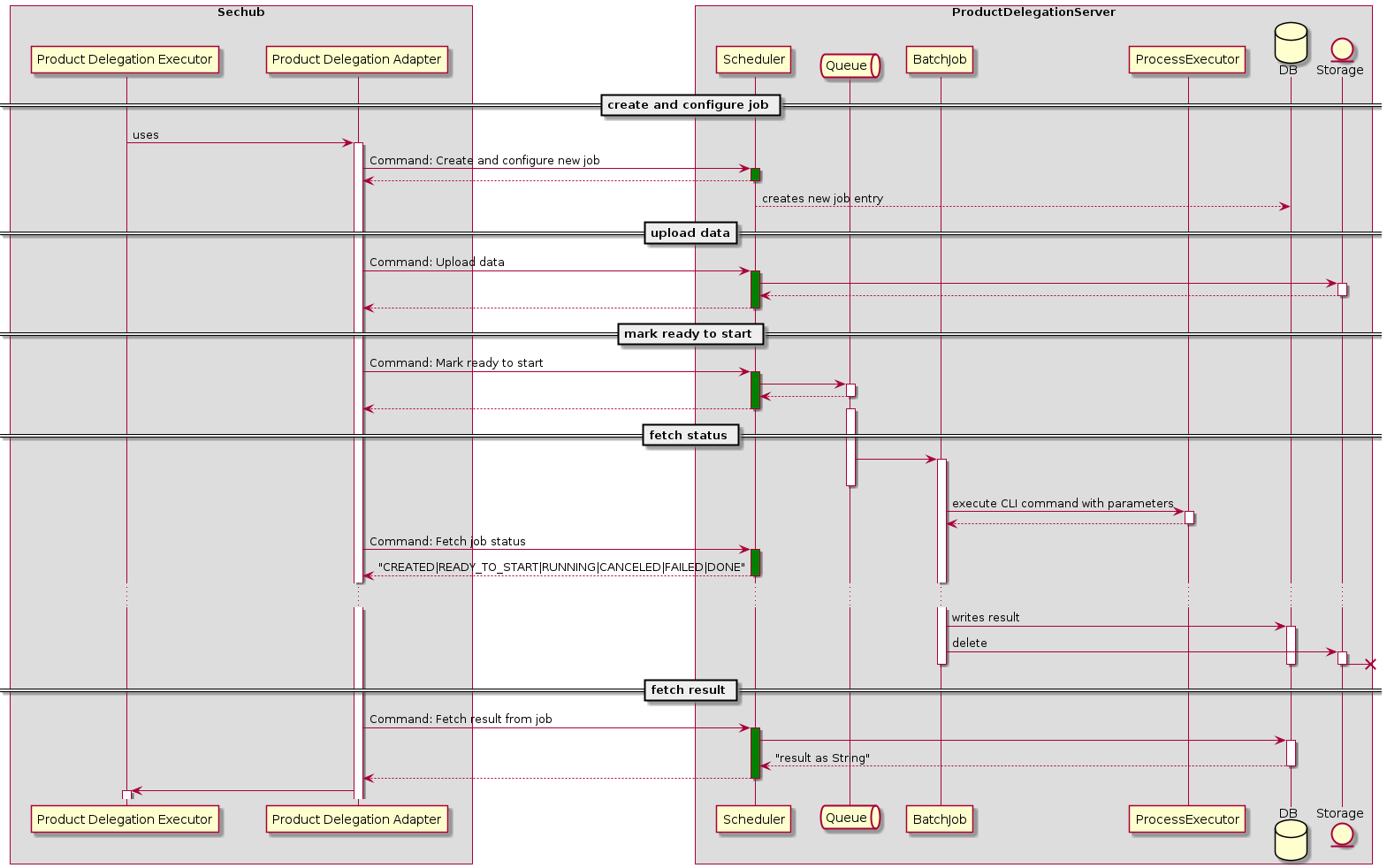
3.1.2. Details about PDS
For more details please refer to the <<https://mercedes-benz.github.io/sechub/latest/sechub-product-delegation-server.html,PDS documentation>> available at
3.1.3. Encryption
3.1.3.1. General
We want
-
Simple encryption rotation approach
In contrast to SecHub, the data in the PDS is only temporary and is not made available for a longer period of time. Subsequent access to encrypted data is also no longer necessary, but only while a SecHub job is running. +
This means we simply accept the situation that a PDS restart with new encryption setup could lead to a situation where a former created job is no longer executable by PDS.
When the encryption changes for a job between its creation and when it begins running, the job will be marked automatically as failed and having encryption out of sync. The PDS product executor at SecHub side will take care of such a situation and will restart a new PDS job (which will then be encrypted correctly again).
-
Full automated
There is no need for manual interaction - means it is not necessary to create any cron jobs or something else to convert non encrypted data to encrypted data or to rotate a password or to use a new encryption method. -
Data protection /Privacy policy
-
Even for administrators it shall not be possible to fetch the information directly
(of course a person who knows the encryption password and has access to the database will always be able to calculate values - but we separate here between administration and operation inside this concept, so protection is fully possible) -
The data must not be accidentally made available in decrypted form - for example through a REST call in which the data object is passed along unencrypted.
-
-
Easy encryption administration
-
It shall be possible for an administrator to configure a new cipher entry at deployment time
-
-
Secure storage of encryption passwords
-
Encryption passwords are always provided via environment entries, we store always the environment variable name to use inside the database but never plain values!
-
3.1.3.2. PDS startup
A PDS server only knows the encryption defined inside two variables:
-
PDS_ENCRYPTION_SECRET_KEY
contains the base64 encoded secret key used for encryption -
PDS_ENCRYPTION_ALGORITHM
contains the information about the used encryption algorithm. Can be
NONE,AES_GCM_SIV_128orAES_GCM_SIV_256.
This setup will be used inside the complete instance as long as it is running. There is no pooling of different encryptions (in constrast to SecHub, where pooling feature exists).
|
If the secret key is not a base 64 value the server startup will fail! |
3.1.3.3. Administration
3.1.3.3.1. Encryption rotation
There is no complete rotation of encryption - old data will have no encryption update.
But an administrator is able to do re-deployment of the PDS cluster and using other secret or algorithm.
This will
-
use new encryption setup for all new PDS jobs
-
keep existing encrypted data as is
-
can lead to a rare race condition when SecHub has created the job with old PDS instance and new PDS instance tries to run the PDS job (the access to the encrypted data is no longer possible)
|
Via auto cleanup the old data will automatically disappear. If an encryption cleanup for PDS via auto cleanup is too late (e.g. credentials were leaked and an update is really urgent) , it is still possible to just delete via SQL all jobs at database which have a timestamp older then the newest deployment time (or just all). |
3.1.3.3.2. Encryption status
There is no direct possibility to check encryption status. But the job contains a creation time stamp and can be mapped to the startup of containers if this would become necessary.
3.1.3.3.3. Cleanup old encrypted data
Auto Cleanup automatically removes old information. This means that old encrypted information (with older encryption settings) automatically disappears after a certain period of time.
Since no other encryption data is persisted except in the PDS job, nothing else needs to be cleaned up.
3.1.3.4. Diagrams

3.1.4. Auto cleanup
The PDS provides an auto cleanup mechanism which will remove old PDS jobs and their data automatically.
The default configuration is set to 2 days. Administrators can change the default configuration via REST .
3.1.5. Storage and sharing
PDS needs - like SecHub - the possiblity to store job data in a central storage location when operating inside a cluster (it’s not clear which cluster member uploads job data and which one does execute the job and need the data at exectuion time).
PDS does use the already existing sechub-storage-* libraries which provide storage mechanism for S3 and
for shared volumes.
|
The next examples explain the different situations appearing for a PDS cluster executing product "XYZ", but of course this applies to multiple clusters for different products as well |
|
For non clustered environment "shared volumes" can also be local file system paths like
|
|
When talking about a NFS or a shared volume here, this is always meant to be a file system path. It’s important to mount a NFS at a local file path for the PDS server when using a shared volume. URLs are NOT supported - only file paths. So you must mount your network file storage to a local file location! For example: a base path for a shared volume could look like: |
3.1.5.1. Shared S3 storage
In the next example PDS and SecHub are using the same S3 bucket to store files uploaded by the user.
We have two different scenarios here:
-
Product executor configuration
pds.config.use.sechub.storageistrue
In this case the way is exactly as shown in next picture:-
The user uploads job data for a SecHub job and it is stored at shared S3 bucket (blue lines).
-
When SecHub job is starting it will create a PDS job but does not upload any additional data.
-
When PDS job is starting the PDS server will fetch workspace files from existing SecHub job data (red lines).
-
The storage path location is for PDS and SecHub
${sharedS3Bucket}/jobstorage/${secHubJobUUID}/
-
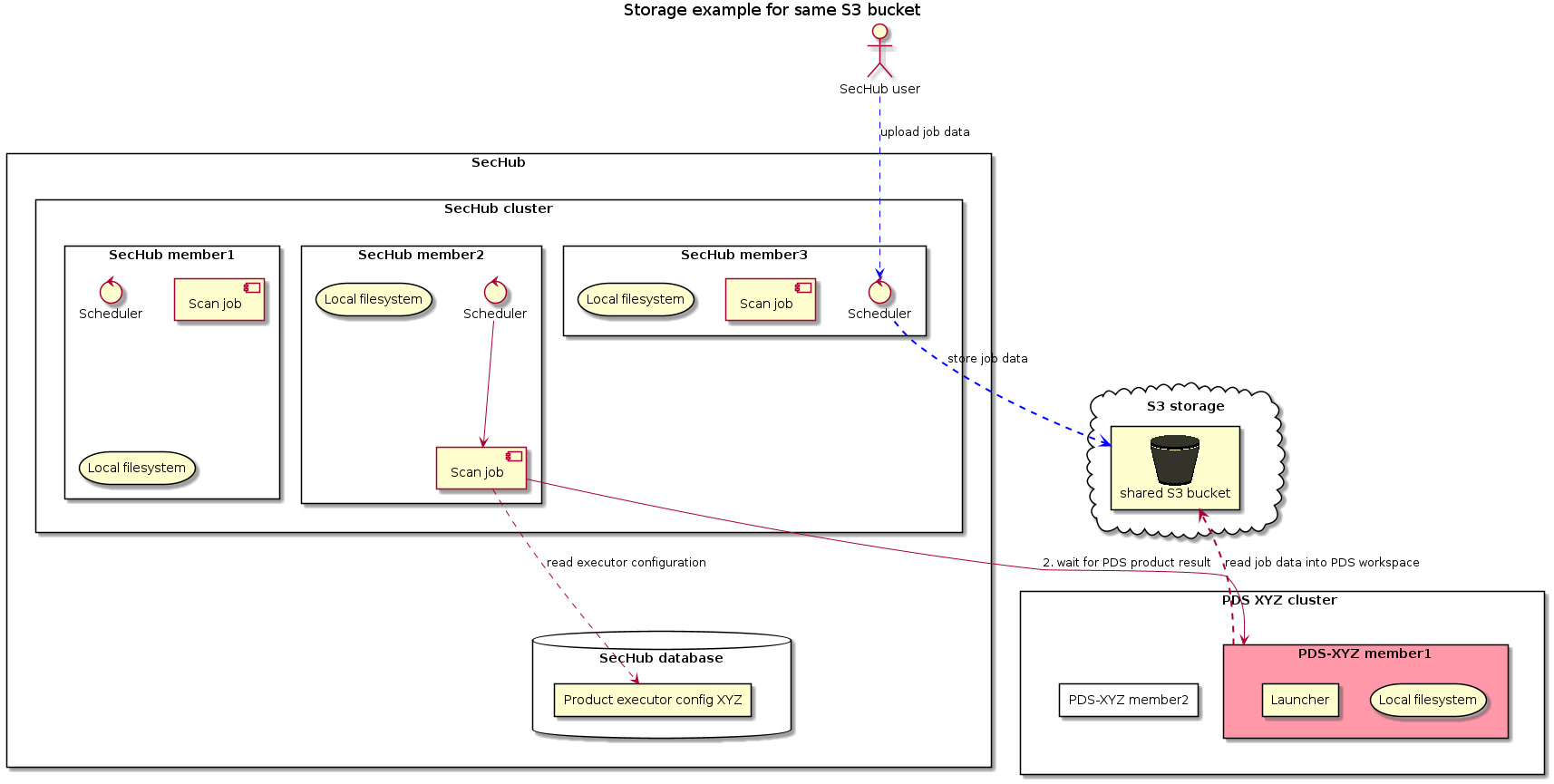
-
Product executor configuration
pds.config.use.sechub.storageis NOTtrue
In this case the way is NOT like in picture before, but more like in Different S3 storages. Read there for more details - it’s the same - except there are not 2 different S3 buckets but only one.
3.1.5.2. Different S3 storages
In the next example PDS and SecHub are using different S3 buckets as storage.
We have two different scenarios here:
-
Product executor configuration
pds.config.use.sechub.storageis NOTtrue
In this case the way is exactly as shown in next picture:-
The user uploads job data for a SecHub job and it is stored at shared S3 bucket (blue lines).
-
The storage path location for SecHub is
${sechubS3Bucket}/jobstorage/${secHubJobUUID}/ -
When SecHub job is starting it will create and initialize a PDS job by uploading all existing job data by PDS rest API. This will store job data at PDS storage. (green lines).
-
When PDS job is starting, the PDS server will fetch workspace files from its PDS job data (red lines).
-
The storage path location for PDS is
${pdsS3Bucket}/pds/${pdsProductIdentifier}/${pdsJobUUID}/
-
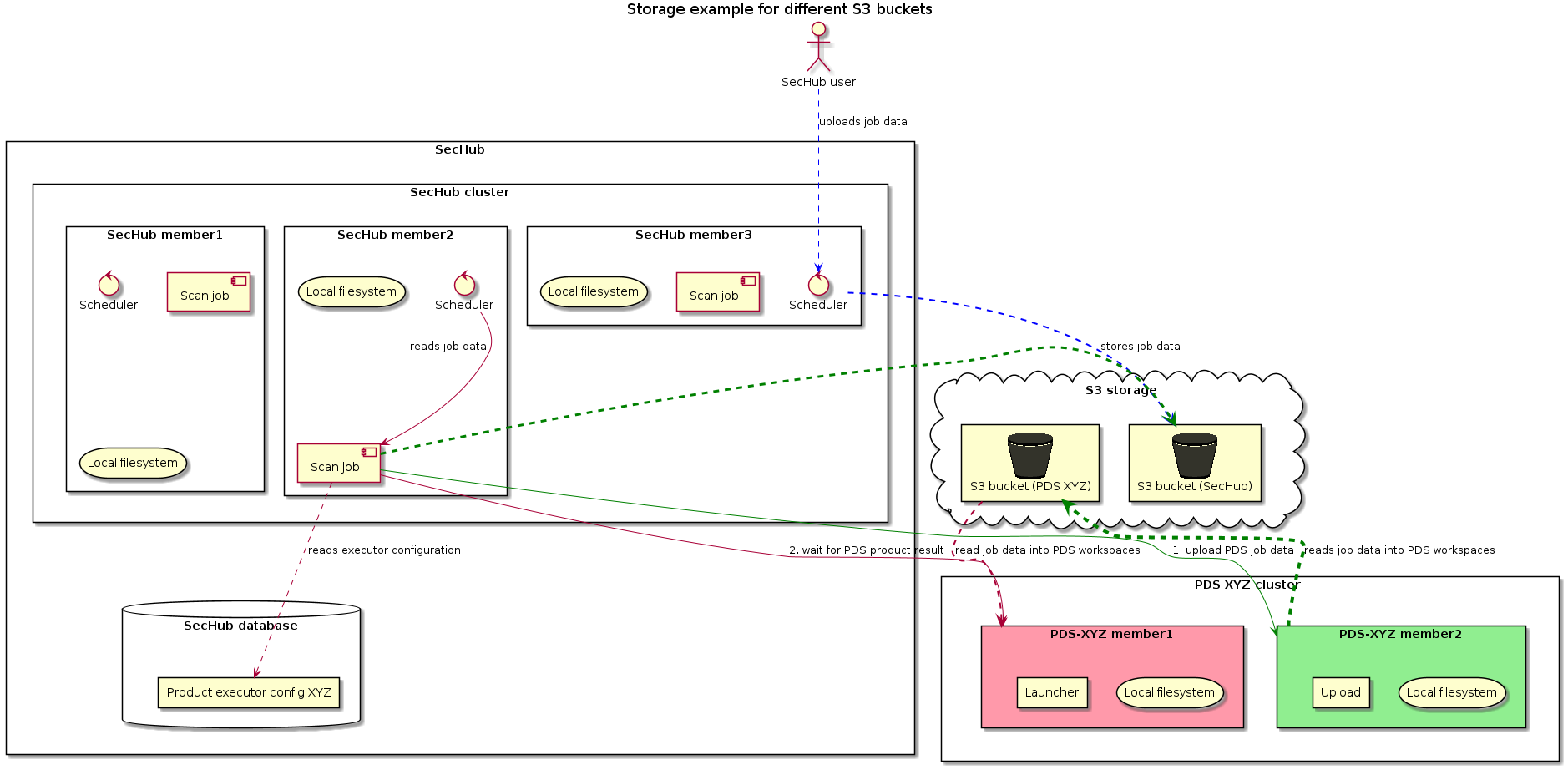
-
Product executor configuration
pds.config.use.sechub.storageistrue
| This will NOT WORK! The job storage will not be found and an error will be thrown at job execution time. |
3.1.5.3. Same shared volume (NFS)
In the next example PDS server and SecHub are using same shared volume as storage.
We have two different scenarios here:
-
Product executor configuration
pds.config.use.sechub.storageistrue
In this case the way is exactly as shown in next picture:-
The user uploads job data for a SecHub job and it is stored at shared volume (blue lines).
-
When SecHub job is starting it will create a PDS job but does not upload any additional data.
-
When PDS job is starting the PDS server will fetch workspace files from existing SecHub job data (red lines).
-
The storage path location is for PDS and SecHub
${sharedVolumeBasePath}/jobstorage/${secHubJobUUID}/
-
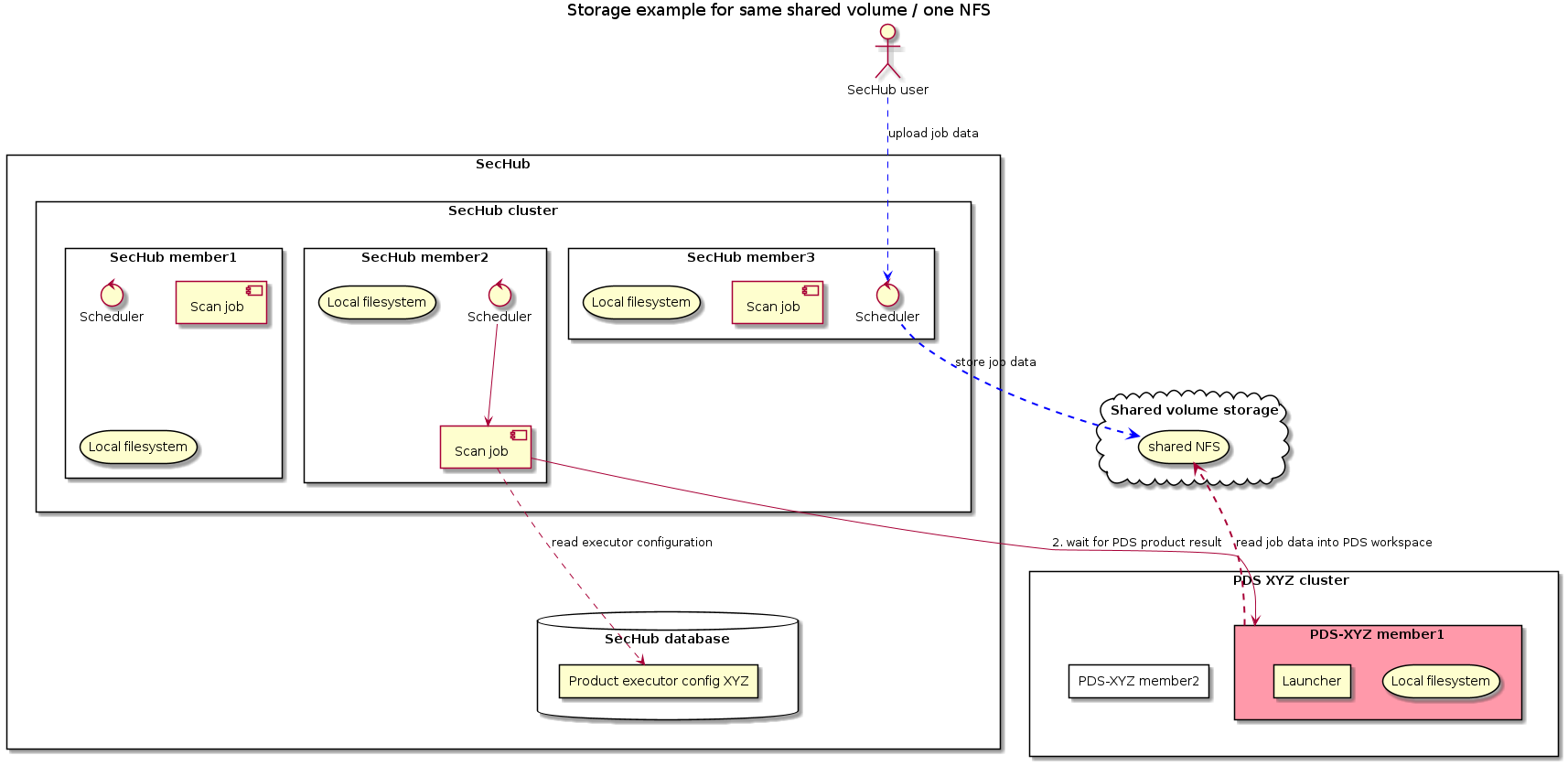
-
Product executor configuration
pds.config.use.sechub.storageis NOTtrue
In this case the way is NOT like in picture before, but more like in Different shared volumes. Read there for more details - it’s the same - except there are not 2 different NFS but only one.
3.1.5.4. Different shared volumes (NFS)
In the next example PDS and SecHub are using different shared volumes as storage.
We have two different scenarios here:
-
Product executor configuration
pds.config.use.sechub.storageis NOTtrue
In this case the way is exactly as shown in next picture:-
The user uploads job data for a SecHub job and it is stored at SecHub shared volume (blue lines).
-
The storage path location for SecHub is
${sechubSharedVolumeBasePath}/jobstorage/${secHubJobUUID}/ -
When SecHub job is starting it will create and initialize a PDS job by uploading all existing job data by PDS rest API. This will store job data at PDS storage. (green lines).
-
When PDS job is starting, the PDS server will fetch workspace files from its PDS job data (red lines).
-
The storage path location for PDS is
${pdsSharedVolumeBasePath}/pds/${pdsProductIdentifier}/${pdsJobUUID}/
-
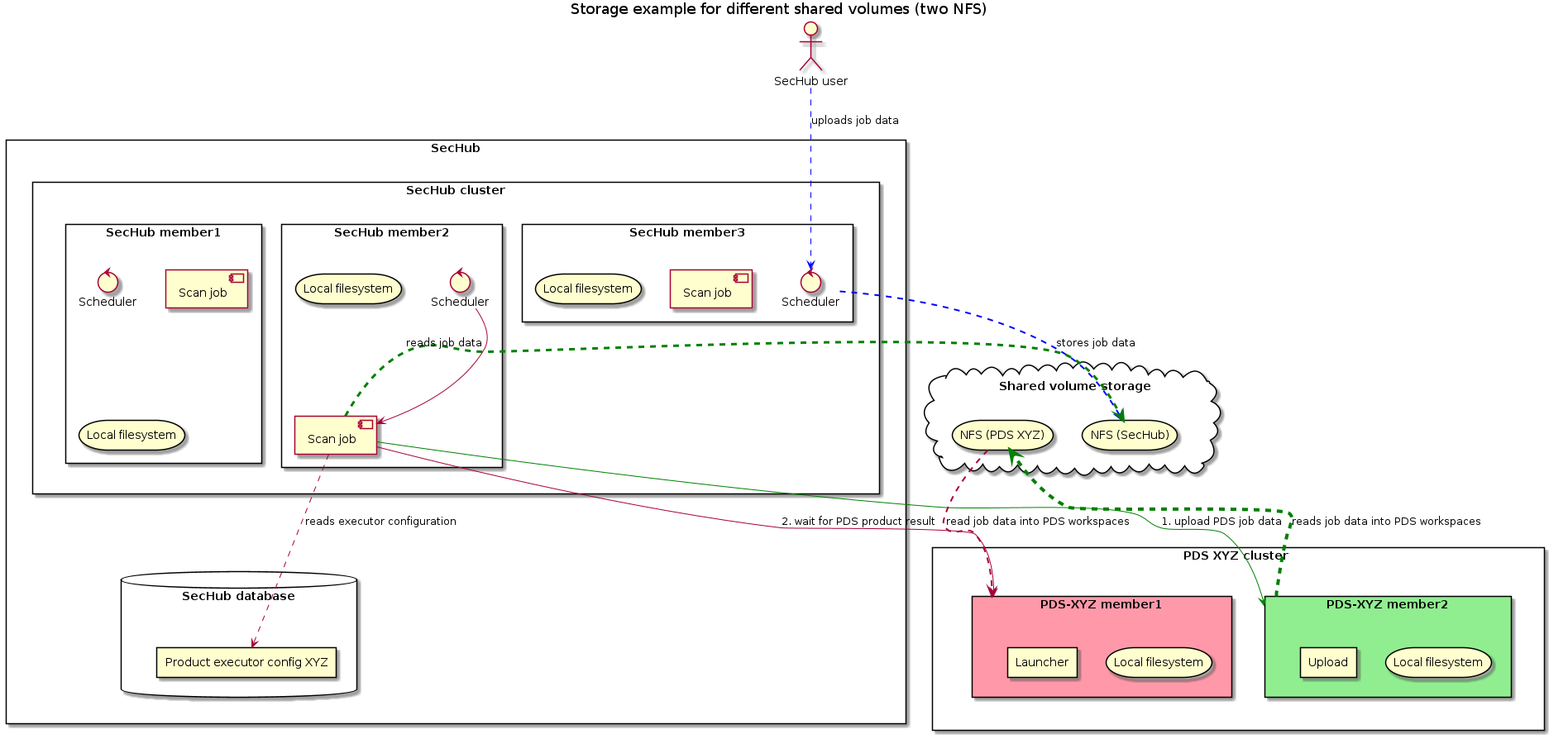
-
Product executor configuration
pds.config.use.sechub.storageistrue
| This will NOT WORK! The job storage will not be found and an error will be thrown at job execution time. |
3.1.5.5. Mixing S3 and shared volume (NFS)
This example is only mentioned for the sake of completeness: It is the same as before described for different S3 and different shared volumes:
pds.config.use.sechub.storage cannot be used in this case.
When not reusing SecHub storage, this scenario does work also well. In the next picture, SecHub itself would use a S3 storage and he
PDS instances for product XYZ would use a NFS to store job data. But of course it could be also the other way.
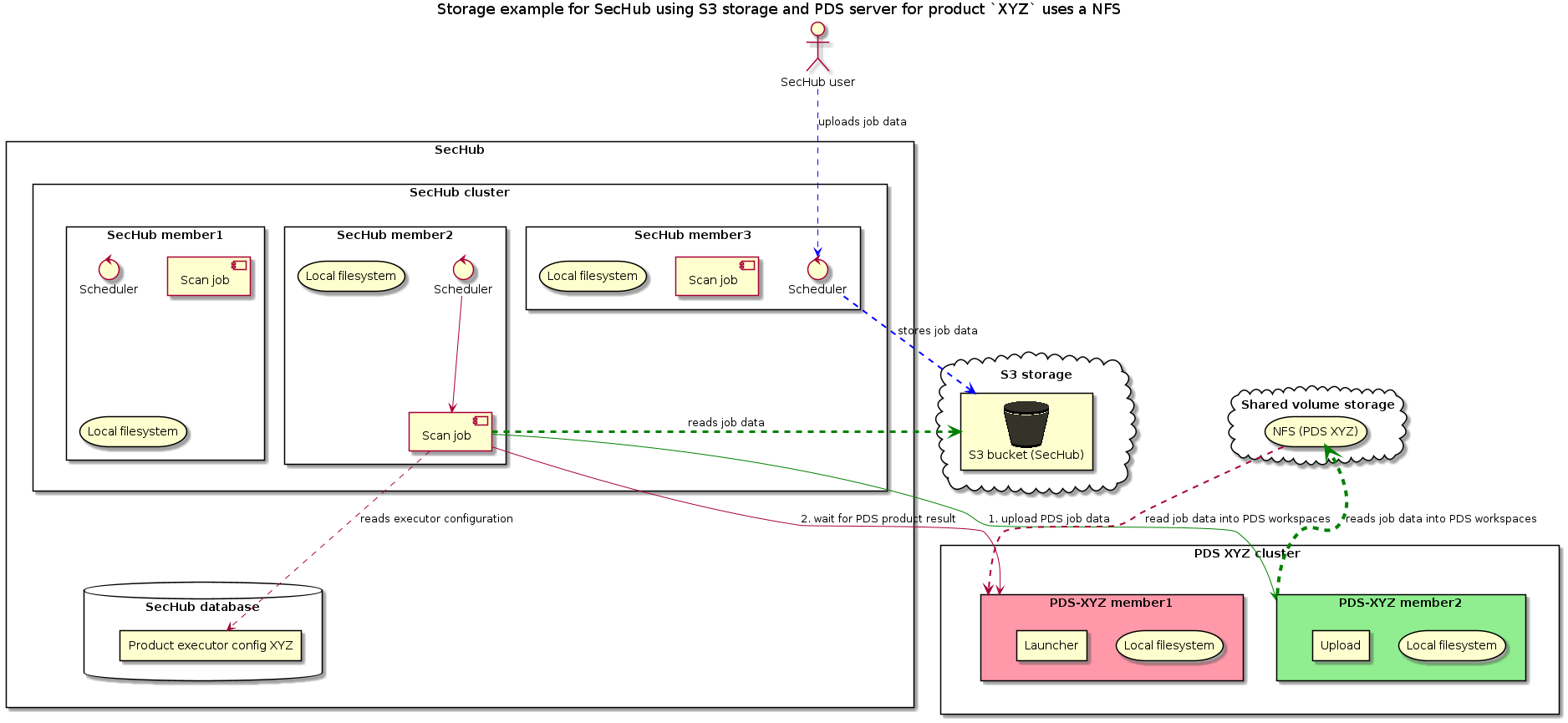
3.1.6. Process execution
PDS instances are executing so called caller scripts by spanning a new process. At this time
dedicated environment variables are automatically injected and available inside the scripts.
|
When implementing a new PDS product integration you should always start with a normal,
executable script (e.g. So you can simply call your script standalone and when it works you just have to create the PDS configuration file and make the script callable. |
3.1.6.1. How PDS provides output and error stream content of running jobs in clustered environments
We use error.txt and output.txt inside the workspace location of
a running PDS job.
The PDS job process does not store the files on a shared volume or S3 bucket but on the local file system (like done for uploaded source files for example).
So we can easily write those text content from the files to our database when the OS process (executing PDS caller script) has finished or failed, because at this time we have direct access to the files.
But when an administrator wants to get the current output for a running job / operation this becomes tricky in a clustered environment, because the process stream data is only available on the machine where the job is executed. Using a loadbalancer we do not know which machine will be used for the REST operation.
So it becomes necessary, that the executing cluster member will store the error and output text data in database to provide this cluster wide.
On the other hand it shall not slow down or block the execution machine because of permanent updates inside the DB. If an admin wants to check the output or error stream content of a running job, the information shall be gathered on demand. But when the job has finished (no matter if canceled, done or failed) the information will always be written to DB.
The next figure gives an overview about the workflow to achieve this goal:

3.1.6.2. How PDS handles meta data
3.1.6.2.1. General
When communication of PDS with the used product is stateful and is a long running operation, it can be useful to store state information as meta data.
One use case is the restart possibility for a SecHub job. Other ones are debugging or trace information. The meta data from PDS can be reused by SecHub.
An administrator is able to fetch job meta data via REST .
|
Most times PDS solutions do not need to store special meta data information: When the PDS job starts a CLI tool, the result or the failure will just be returned to the SecHub side. If it shall be done again (because of on failure) just a new PDS job will be started. If a PDS job has meta data this means it should be restarted |
3.1.6.2.2. PDS job meta data file
Access mechanism
A PDS launcher script has no access to the PDS database.
If meta data shall be read or written, we have a dedicated workspace file to write into.
The location of the file is available with environment variable PDS_JOB_METADATA_FILE.
Exchanging meta data with SecHub
The PDS executors inside SecHub are able to access meta data (e.g. for restart handling).
See next diagram for details:
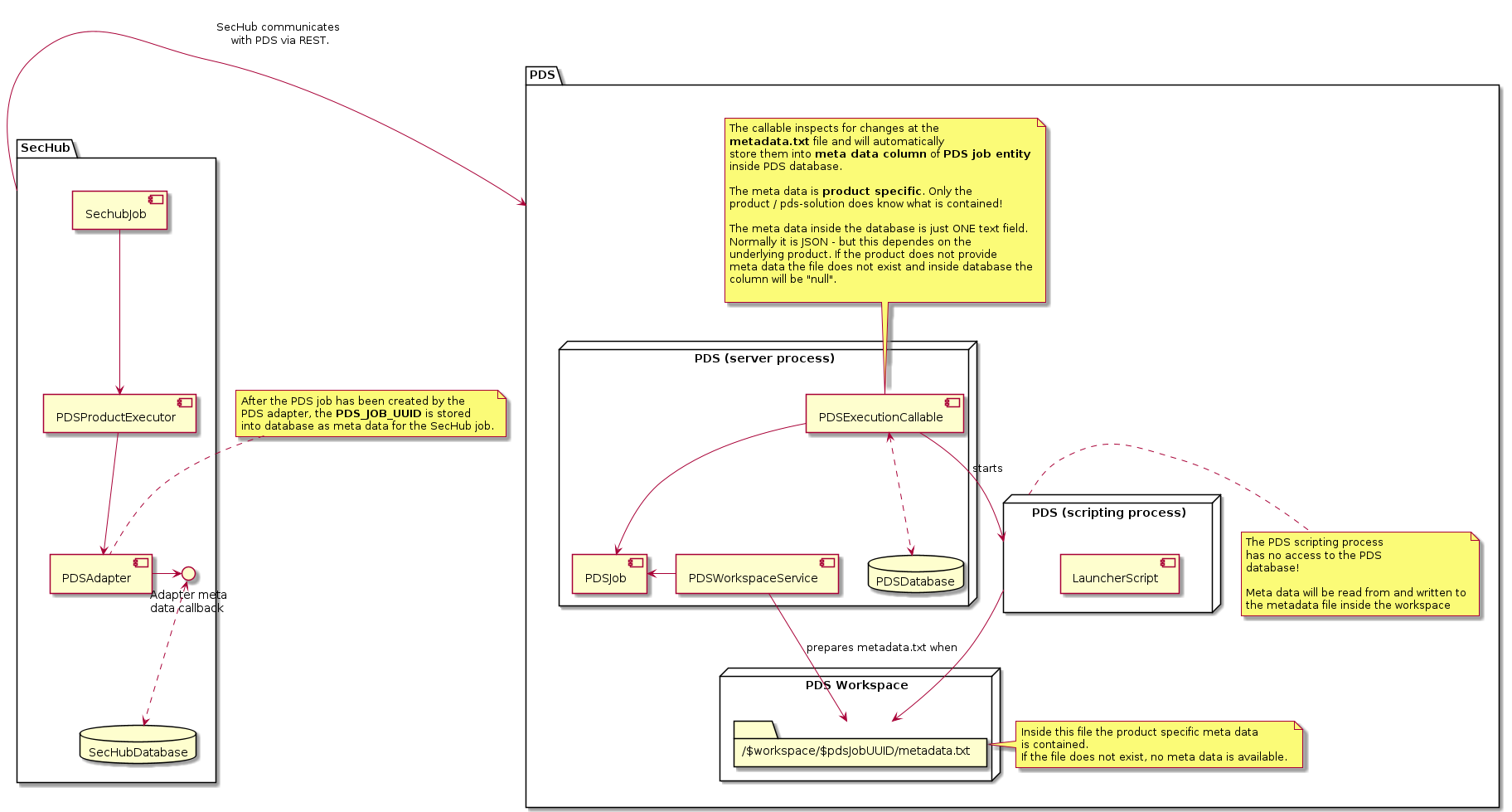
The meta data file must have the same meta data syntax as in SecHub product results:
{
"metaData" : {
"key1" : "value1", (1)
"key2" : "value2"
}
}| 1 | Inside the metaData element we can provide any kind of key value combination. |
3.1.6.2.3. Checkmarx PDS solution adapter meta data handling
The PDS solution for Checkmarx does reuse the already existing CheckmarxAdapter class.
A sechub-wrapper-checkmarx gradle project was introduced which contains a simple spring boot
CLI application which uses the adapter for communication. The adapter callback is not directly
reading or writing to the database but uses the metadata.txt file from the PDS workspace.
Look at next figure for more details:
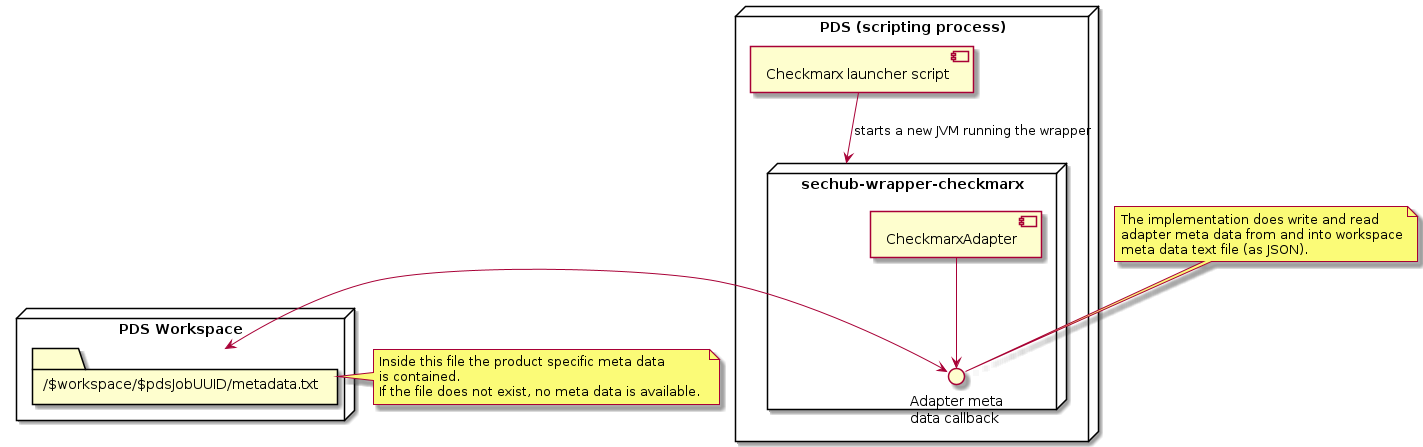
3.1.6.3. How PDS handles storage data
The PDS does automatically fetch uploaded files from shared storage
temporary into its local filesystem. After the scan has been done, the temporary local files
will be automatically deleted.
3.1.6.3.1. Source code fetching
Source code is always contained in a file called sourcecode.zip.
When a PDS starts a new job, it will fetch the complete ZIP file from storage
to it’s local storage at
${PDSJobWorkspaceLocation}/upload/sourcecode.zip.
Afterwards the relevant sources will be automatically extracted by inspecting the archive data structure.
3.1.6.3.2. Binaries fetching
Binaries are always contained in a file called binaries.tar.
When a PDS starts a new job and the scan does references a binary data section, it will fetch
the complete TAR file from storage to it’s local storage at
${WorkspaceLocation}/upload/binaries.tar.
Afterwards the relevant binaries will be automatically extracted by inspecting the archive data structure.
3.1.6.3.3. Data structure inside TAR and ZIP files
The data structure inside TAR and ZIP files contains
data configuration parts inside __data__ folder.
|
Before we introduced the possibility to define referenceable data inside a
SecHub configuration, we already provided a For source scans this a more convenient way and we wanted to keep this possiblity - also for backward compatibility with existing SecHub configuration files. So this is the reason, why data is contained inside |
${content} (1)
__data__/unique-name-1/${content} (2)
__data__/unique-name-2/${content} (3)
...| 1 | code scan embedded file system data |
| 2 | content of a data configuration with name "unique-name-1" |
| 3 | content of a data configuration with name "unique-name-2" |
Here an example:
{
"data": {
"sources": [ (1)
{
"name": "reference-name-sources-1", (2)
"fileSystem": {
"files": [
"somewhere/file1.txt",
"somewhere/file2.txt"
],
"folders": [
"somewhere/subfolder1",
"somewhere/subfolder2"
]
},
"excludes": [
"**/mytestcode/**",
"**/documentation/**"
],
"additionalFilenameExtensions": [
".cplusplus",
".py9"
]
}
],
"binaries": [ (3)
{
"name": "reference-name-binaries-1", (4)
"fileSystem": {
"files": [
"somewhere/file1.dll",
"somewhere/file2.a"
],
"folders": [
"somewhere/bin/subfolder1",
"somewhere/bin/subfolder2"
]
}
},
{
"name": "reference-name-binaries-2", (5)
"fileSystem": {
"files": [
"somewhere-else/file1.dll",
"somewhere-else/file2.a"
],
"folders": [
"somewhere-else/bin/subfolder1",
"somewhere-else/bin/subfolder2"
]
}
}
]
}
}| 1 | source definition - these structure parts are inside the sourcecode.zip file |
| 2 | Name of one source data configuration |
| 3 | binaries definition - these structure parts are inside the binaries.tar file |
| 4 | Name of the first binaries data configuration |
| 5 | Name of the second binaries data configuration |
The example json configuration defines following content structure inside the upload files:
__data__/
reference-name-sources-1/ (2)
somewhere/
file1.txt
file2.txt
subfolder1/
example-content.py9
subfolder2/
example-content.cplusplus
example-content.txtThe example json configuration would lead to a TAR file containing:
__data__/
reference-name-binaries-1/(4)
somewhere/
file1.dll
file2.a
subfolder1/
example-content.bin
subfolder2/
example-content.img
reference-name-binaries-2/(5)
somewhere-else/
file1.dll
file2.a
subfolder1/
example-content.bin
subfolder2/
example-content.imgHow to support custom archive uploads by Web UI?
Every scan configuration which relies on file data - except the codeScan legacy way - needs at least one
reference to sources or binaries inside the data section.
With the Web UI users shall be able to upload custom source and/or binary archives and start a job directly.
But most users just want to create a simple archive with their sources (or binaries) inside and do not want
to bother with data sections. While creating a new SecHub job, the Web UI generates a temporary SecHub
configuration file which must reference files related to the root folder of the custom user archives.
To provide this in a convenient but still compatible way, following unique reference names/ids were introduced:
-
__sourcecode_archive_root__
(for source code files at root level in a ZIP) -
__binaries_archive_root__
(for binary files at root level in a TAR)
They can be used like any other reference name within a configuration.
But they cannot be defined in a data section of a configuration, since their target, the root folder of the
respective archive, is always present anyway. The Web UI can now generate a temporary config file by using the
reserved reference names.
|
If a data section of a configuration contains a reserved reference name the configuration is invalid for the server.
If the custom archive contains folders directly below |
|
The SecHub go client will always produce archives with |
3.1.6.3.4. Automated Extraction of relevant parts
Only files and folders which are available for the configured scan type will be automatically
extracted!
The artificial path element _data_ and the reference name will not be contained in extracted
folders.
|
Please read the SecHub technical documentation for more details about the data configuration. You will find it described at https://mercedes-benz.github.io/sechub. |
Automated extraction of source code
Let’s assume PDS has fetched sourcezip.zip which contains following structure:
__data__/
license-sources/
somewhere/
file1a.txt
subfolder1/
file1b.txt
file2.txt
other-sources/
file3.txtand a SecHub configuration file like this:
{
// .. assume data section and other parts are configured correctly ..
"licenseScan": {
"use" : ["license-sources"]
},
"codeScan": {
"use" : ["other-sources"]
}
}In the example the SecHub configuration has a license scan configured which references
license-sources data configuration and a code scan which references other-sources.
The PDS for license scanning will only extract license-sources:
${PDSJobWorkspaceLocation}/upload/unzipped/sourcecode
somewhere/
file1a.txt
subfolder1/
file1b.txt
file2.txt|
|
Automated extraction of binaries
Let’s assume PDS has fetched binaries.tar which contains following structure:
__data__/
license-binaries/
somewhere/
file1a.bin
subfolder1/
file1b.bin
file2.bin
other-binaries/
file3.binand a SecHub configuration file like this:
{
// .. assume data section and other parts are configured correctly ..
"licenseScan": {
"use" : ["license-binaries"]
},
"codeScan": {
"use" : ["other-binaries"]
}
}In the example the SecHub configuration has a license scan configured which references
license-binaries data configuration and a code scan which references other-binaries.
The PDS for license scanning will only extract license-binaries:
${PDSJobWorkspaceLocation}/upload/extracted/binaries
somewhere/
file1a.bin
subfolder1/
file1b.bin
file2.bin3.1.6.4. How PDS handles user messages

3.1.6.5. How PDS handles execution events
3.1.7. PDS events
Sometimes it is necessary that the PDS inform the script about changes. This can be done by execution events.
3.1.7.1. Overview
The product adapter is able to read and write events into a dedicated folder inside the workspace.
This is utilized by the PDSWorkspaceService class.
| As an example for an event the PDS cancel service calls are additionally shown (grey) |

3.1.7.2. Handling events in launcher script
The launcher scripts (or in started wrapper applications by these scripts) have the
environment variable PDS_JOB_EVENTS_FOLDER injected.
The launcher part must inspect the folder periodically for new
|
Most PDS solutions do not need to inspect for events. It depends on the situation if there is any special event treatment necessary. An example: |
3.1.7.3. How PDS product executors configure the PDS adapter
The different PDS product executors have different config builders which inherit from different abstract base classes
(e.g. AbstractCodeScanAdapterConfigBuilder). We have no multi inheritance in Java, but we do also not
want to implement the setup logic (which is complicated) for every PDS product executor again.
There is a specialized adapter configuration strategy for PDS standard setup: PDSAdapterConfigurationStrategy.
3.1.7.4. Overview
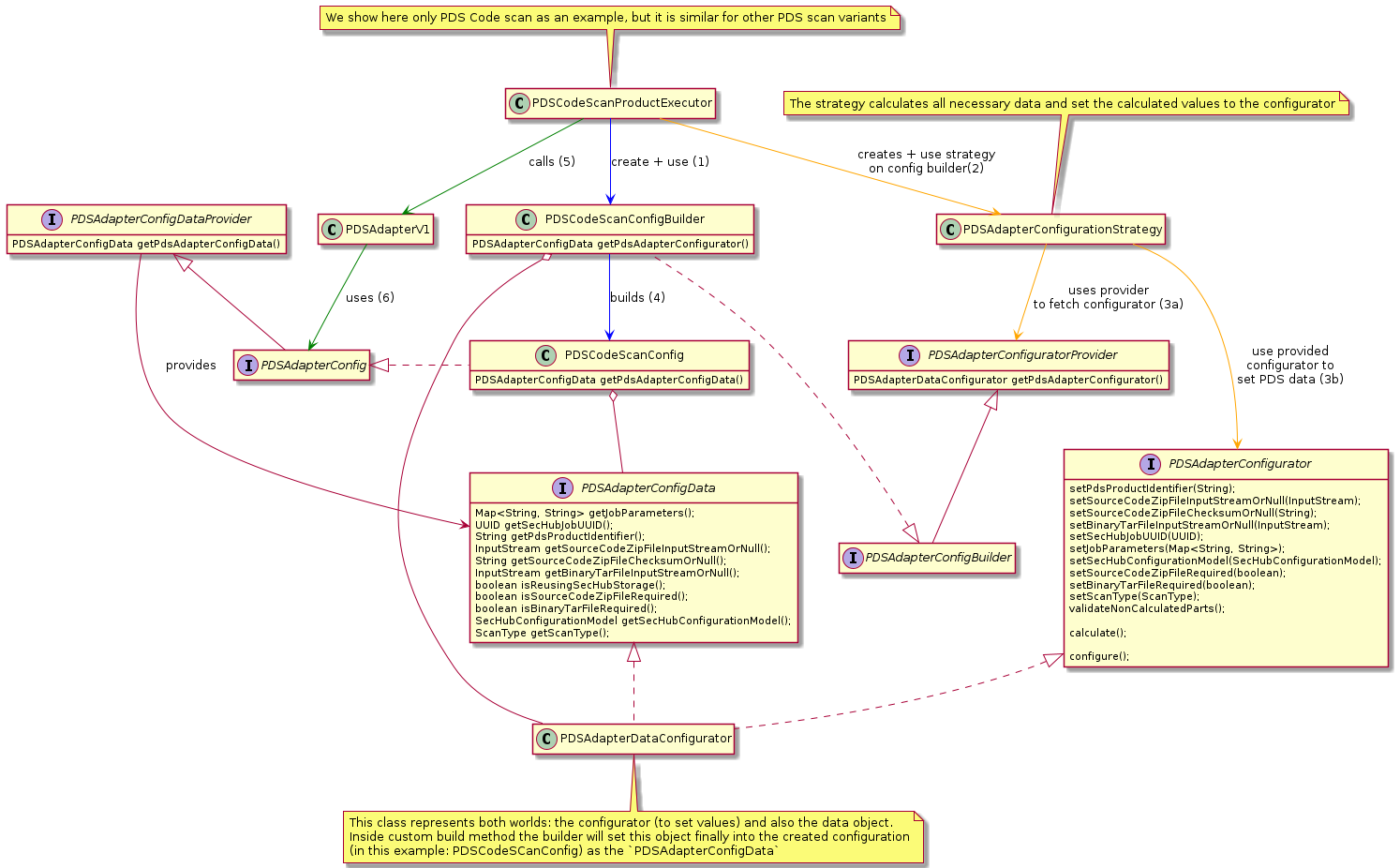
3.1.7.5. How PDS handles deployment with running jobs
This is done following way:
SIGTERM signal from OS is recognized and still running jobs are set to state READY_FOR_RESTART.
Because the job stores its state via meta data (see PDS meta data ) it is possible reuse/relaunch the job from new instances. The PDS scheduler mechanism to determine next job to start handles this state before others.
|
K8s (Kubernetes) sends a SIGTERM signal when doing rolling updates. Means we have here a zero down time with K8s + PDS. |
|
Other signals (e.g. |
3.1.8. SecHub integration
3.1.8.1. Executors and Adapters
3.1.8.1.1. Executors
With PDS there is a default REST API available.
For different scanTypyes there will be dedicated PDSExecutors
(PDSWebScanExecutor, PDSInfraScanExecutor, etc., etc.)
3.1.8.1.2. Adapters
The Adapter will always be the same, but filled with other necessary parameters.
| So there will be no need to write any adapter or executor when using PDS! |
3.1.9. HowTo integrate a new product via PDS
Having new security product XYZ but being a command line tool, we
-
create an environment (e.g. a docker container) where all your needed parts are integrated. E.g. bash shell, tools, the product and its dependencies etc.
-
create an executable starter script (e.g. bash) which
-
calls the product
-
does system out/err to standard pipes
-
writes the product result report to relative path
./output/result.txt
-
-
create a
PSDconfiguration file and fill with necessary data, see PDS server configuration file -
start wanted amount of
ProductDelegationServerinstances with dedicated configuration setup to have a clustered, server ready execution of CLI security products. If you want your PDS to be started inside a cluster you have to setup load balancing etc. by your own. For example: When using Kubernetes you normally would do this by just defining aServicepointing to yourPODs. -
test via developer admin UI if the servers are working:
-
create test job, remember PDS job uuid
-
upload data
-
mark job as ready to start
-
check job state
-
fetch result and inspect
-
-
when former test was successful
-
Define executor on SecHub server side - will be implemented with #148
-
When your product uses sereco general report format your are done- will be implemented with #283 otherwise SERECO must have a logic to import custom format for the PRODUCT - means needs an implementatiion
-
-
test via SecHub client by starting a new SecHub job which shall use the product and verify results
|
Output and error stream of a PDS launcher script are stored in PDS database as plain text! Means: NEVER log any sensitive data in launcher scripts! If you want to give hints for debugging etc. you have to mask the information in log output. |
4. Runtime view
4.1. Configuration
4.1.1. Operating the SecHub PDS
Here you can find ready-to-use container images of the PDS and SecHub’s PDS solutions (security scan products).
4.1.1.1. Docker
The public Docker images can be found at https://github.com/mercedes-benz/sechub/packages?q=pds
A SecHub PDS solution can be simply run like this (example: pds-gosec solution)
docker run ghcr.io/mercedes-benz/sechub/pds-gosec4.1.1.2. Kubernetes
We also provide Helm charts for above container images.
You should use a copy of the values.yaml and adapt it to your needs.
Example: pds-gosec solution
helm pull oci://ghcr.io/mercedes-benz/sechub/helm-charts/pds-gosec
tar zxf pds-gosec-*.tgz
cp pds-gosec/values.yaml pds-gosec.yaml
# Edit "pds-gosec.yaml" file and change it to suit your needs
# Deploy SecHub server to your Kubernetes:
helm install pds-gosec pds-gosec/ -f ./pds-gosec.yaml
In order to use the PDS solution from SecHub, you need to activate it in the values.yaml of SecHub server.
|
4.1.2. Profiles / running the SecHub PDS
4.1.2.1. Production mode
You can start a PDS in production profile which requires a running PostgreSQL database. Please refer also to PostgreSQL configuration for database setup which must be done before.
Example:
java -jar Dspring.profiles.active=pds_prod sechub-pds-0.25.0.jar
| There are some more mandatory parameters, please refer to general configuration |
4.1.2.2. Integration test mode
You can start a PDS in integration test mode if you just want to test
Example:
java -jar -Dspring.profiles.active=pds_integrationtest,pds_h2 sechub-pds-0.25.0.jar
4.1.2.3. Logging
4.1.2.3.1. Default output
PDS uses per default logging to stdout. In case you are running on Kubernetes or similar platforms you can use
fluentd to gather the log output.
4.1.2.3.2. Logstash support
When you want to use logstash you just have to set the environment variable
LOGGING_TYPE to LOGSTASH_JSON before server starts.
4.1.3. Database configuration
4.1.3.1. PostgreSQL
First of all install a PostgreSQL database.
Then define following environment entries before you start the server with active postgres profile:
-
POSTGRES_DB_URL
-
POSTGRES_DB_USERNAME
-
POSTGRES_DB_PASSWORD
Examples:
POSTGRES_DB_URL=jdbc:postgresql://127.0.0.1:49153/pds-gosec POSTGRES_DB_USERNAME=pds-gosec-pg-admin POSTGRES_DB_PASSWORD=a-very-strong-password...
4.1.4. General configuration
PDS can be configured by keys on server startup. With spring it is is possible to define the keys as Java system properties but also as environment entries.
E.g. a key like pds.server.debug can be set with -Dpds.server.debug=true
or with an environment entry PDS_SERVER_DEBUG which
is e.g. more suitable for a kubernetes cluster deployment.
|
Even when it is possible to configure If you define those parts not as environment variables, |
| Key or variable name | Default | Description |
|---|---|---|
PDS_ENCRYPTION_ALGORITHM |
The encryption type. Allowed values are: NONE, AES_GCM_SIV_128 or AES_GCM_SIV_256 This must be defined as an environment variable! |
|
PDS_ENCRYPTION_SECRET_KEY |
The secret key used for encryption. It must be base64 encoded, otherwise it is not accepted. This must be defined as an environment variable! |
| Key or variable name | Default | Description |
|---|---|---|
pds.config.cancelrequest.minutes.before.treated.orphaned |
60 |
The time in minutes after which a cancel job request is treated as orphaned. |
pds.config.job.stream.cachetime |
2000 |
PDS job stream data caching time in milliseconds. This defines the maximum period of time between an update time stamp and the request timestamp in database where current data is handled as still valid |
pds.config.job.stream.check.retries |
10 |
Maximum amount of tries to check if a stream data refresh has been handled (stream data has been updated) |
pds.config.job.stream.check.timetowait |
500 |
Defines time in milliseconds for PDS job stream data update checks after job has been marked as necessary to have stream data refresh |
pds.config.job.stream.mark.retries |
3 |
Maximum amount of retries to mark job stream data refresh |
pds.upload.maximum.bytes |
52428800 |
Define the maximum amount of bytes accepted for uploading files. The default when not set is 52428800 (50 MiB) |
| Key or variable name | Default | Description |
|---|---|---|
PDS_ADMIN_APITOKEN |
Administrator api token. This must be defined as an environment variable! |
|
PDS_ADMIN_USERID |
Administrator user id. This must be defined as an environment variable! |
|
PDS_TECHUSER_APITOKEN |
Techuser user api token. This must be defined as an environment variable! |
| Key or variable name | Default | Description |
|---|---|---|
PDS_TECHUSER_USERID |
Techuser user id. This must be defined as an environment variable! |
| Key or variable name | Default | Description |
|---|---|---|
pds.server.debug |
false |
When enabled, additional debug information are returned in case of failures. Do NOT use this in production. |
pds.server.errorcontroller.log.errors |
true |
When enabled, additional debug information are returned in case of failures. Do NOT use this in production. |
| Key or variable name | Default | Description |
|---|---|---|
pds.archive.extraction.max-directory-depth |
Defines the maximum directory depth for an entry inside the archive |
|
pds.archive.extraction.max-entries |
Defines how many entries the archive may have |
|
pds.archive.extraction.max-file-size-uncompressed |
Defines the max file size of the uncompressed archive (e.g.: 10KB or 10mb) |
|
pds.archive.extraction.timeout |
Defines the timeout of the archive extraction process |
|
pds.config.execute.queue.max |
50 |
Set amount of maximum executed parts in queue for same time |
pds.config.execute.worker.thread.count |
5 |
Set amount of worker threads used for exeuctions |
pds.config.product.timeout.max.configurable.minutes |
4320 |
Set maximum configurable time in minutes for parameter: |
pds.config.product.timeout.minutes |
120 |
Set maximum time a PDS will wait for a product before canceling execution automatically. This value can be overriden as a job parameter as well. |
pds.workspace.autoclean.disabled |
false |
Defines if workspace is automatically cleaned when no longer necessary - means launcher script has been executed and finished (failed or done). This is useful for debugging, but should not be used in production. |
pds.workspace.rootfolder |
./workspace/ |
Set PDS workspace root folder path. Each running PDS job will have its own temporary sub directory inside this folder. |
| Key or variable name | Default | Description |
|---|---|---|
pds.migration.flyway.autorepair |
true |
When enabled, flyway migration problems will be automatically repaired |
| Key or variable name | Default | Description |
|---|---|---|
pds.config.heartbeat.enabled |
true |
Configure if heartbeat checks are enabled |
pds.config.heartbeat.verbose.logging.enabled |
false |
Configure if heartbeat verbose logging is enabled |
pds.config.trigger.heartbeat.delay |
60000 |
Delay for heartbeat checks |
pds.config.trigger.heartbeat.initialdelay |
1000 |
Initial delay for heartbeat checks |
| Key or variable name | Default | Description |
|---|---|---|
pds.config.scheduling.enable |
true |
Set scheduler enabled state |
pds.config.trigger.nextjob.delay |
5000 |
delay for next job trigger in milliseconds |
pds.config.trigger.nextjob.initialdelay |
3000 |
initial delay for next job trigger in milliseconds |
| Key or variable name | Default | Description |
|---|---|---|
pds.security.diffiehellman.length |
Define diffie hellman key length, see https://github.com/mercedes-benz/sechub/issues/689 for details |
| Key or variable name | Default | Description |
|---|---|---|
pds.config.file |
./pds-configuration.json |
Define path to PDS configuration file |
pds.startup.assert.environment-variables-used.disabled |
false |
When true, the startup assertion for forcing usage of some environment variables is disabled |
| Key or variable name | Default | Description |
|---|---|---|
pds.storage.s3.accesskey |
undefined |
Defines the access key for used s3 bucket. |
pds.storage.s3.bucketname |
undefined |
Defines the s3 bucket name. |
pds.storage.s3.connection.idle.max.milliseconds |
60000 |
S3 client maximum idle time (in milliseconds) for a connection in the connection pool. |
pds.storage.s3.connection.idle.validate.milliseconds |
5000 |
S3 client time (in milliseconds) a connection can be idle in the connection pool before it must be validated that it’s still open. |
pds.storage.s3.connection.max.poolsize |
50 |
S3 client max connection pool size. |
pds.storage.s3.connection.ttl.milliseconds |
-1 |
S3 client expiration time (in milliseconds) for a connection in the connection pool. -1 means deactivated |
pds.storage.s3.endpoint |
undefined |
Defines the s3 endpoint. |
pds.storage.s3.region |
undefined |
S3 client region. Supported are offical AWS region names and additionally: |
pds.storage.s3.secretkey |
undefined |
Defines the secret key for used s3 bucket. |
pds.storage.s3.signer.override |
AWSS3V4SignerType |
Can be used to override the default name of the signature algorithm used to sign requests. |
pds.storage.s3.timeout.connection.milliseconds |
10000 |
S3 client timeout (in milliseconds) for creating new connections. |
pds.storage.s3.timeout.execution.milliseconds |
0 |
S3 client timeout (in milliseconds) for execution. 0 means it is disabled. |
pds.storage.s3.timeout.request.milliseconds |
0 |
S3 client timeout (in milliseconds) for a request. 0 means it is disabled. |
pds.storage.s3.timeout.socket.milliseconds |
50000 |
S3 client timeout (in milliseconds) for reading from a connected socket. |
pds.storage.sharedvolume.upload.dir |
undefined |
Defines the root path for shared volume uploads - e.g. for sourcecode.zip etc. When using keyword temp as path, this will create a temporary directory (for testing). |
4.1.5. PDS solution configurations
Some of the existing PDS solutions do have special configuration parameters which are listed here inside the following sub chapters:
4.1.5.1. PDS Checkmarx solution
The PDS checkmarx solution does internally use a sechub-wrapper-checkmarx Spring Boot application.
The application is able to use all PDS job parameters and some
additional keys which are listed in the next table.
|
The used Checkmarx wrapper can handle it’s job parameter values as a template by using environment variables from your PDS installation. An example: If your PDS process runs in an environment with variable |
| Job parameter | Type | Description |
|---|---|---|
pds.checkmarx.user |
Mandatory |
The user name used to communicate with Checkmarx. You can use env:$YOUR_USER_VARIABLENAME to use environment variables instead of real credentials. |
pds.checkmarx.password |
Mandatory |
The password used to communicate with Checkmarx. You can use env:$YOUR_PWD_VARIABLENAME to use environment variables instead of real credentials. |
pds.checkmarx.baseurl |
Mandatory |
The base URL of the Checkmarx server. |
pds.checkmarx.engine.configuration.name |
Optional |
The engine to use - when empty, the default engine will be used. |
pds.checkmarx.always.fullscan.enabled |
Optional |
When 'true', Checkmarx will do a full scan and not a delta scan. |
pds.checkmarx.result.check.period.milliseconds |
Optional |
The time period in milliseconds when the next check for Checkmarx resuls will be done. An example: If you define |
pds.checkmarx.result.check.timeout.minutes |
Optional |
The maximum time in minutes when the checkmarx communication does time out and the connection will be terminated. |
pds.checkmarx.mocking.enabled |
Optional |
When 'true' than, instead of the real Checkmarx adapter, a mock adapter will be used. This is only necessary for tests. |
checkmarx.newproject.teamid.mapping |
Mandatory |
Can be either defined directly as job parameter (json mapping), or we can send it automatically by reusing an existing SecHub mapping. As an example: 'pds.config.use.sechub.mappings=checkmarx.newproject.teamid.mapping,checkmarx.newproject.presetid.mapping' |
checkmarx.newproject.presetid.mapping |
Optional |
If not the default preset Id shall be used, it can be either defined directly as job paramter (json mapping), or we can send it automatically by reusing an existing SecHub mapping. As an example: 'pds.config.use.sechub.mappings=checkmarx.newproject.teamid.mapping,checkmarx.newproject.presetid.mapping' |
pds.checkmarx.resilience.badrequest.max.retries |
Optional |
Maximum amounts of retries for bad request handling |
pds.checkmarx.resilience.badrequest.retry.wait.milliseconds |
Optional |
Time in milliseconds to wait before next retry when a bad request happend |
pds.checkmarx.resilience.servererror.max.retries |
Optional |
Maximum amounts of retries for internal server error handling |
pds.checkmarx.resilience.servererror.retry.wait.milliseconds |
Optional |
Time in milliseconds to wait before next retry when an internal server error happend |
pds.checkmarx.resilience.networkerror.max.retries |
Optional |
Maximum amounts of retries for network error handling |
pds.checkmarx.resilience.networkerror.retry.wait.milliseconds |
Optional |
Time in milliseconds to wait before next retry when a network error happend |
4.2. Tech user credentials
Either use system properties
pds.techuser.userid pds.techuser.apitoken
or environment variables
PDS_TECHUSER_USERID PDS_TECHUSER_APITOKEN
to define user credentisals. For apitoken please define encrypted password in spring boot
style - e.g. {noop}unencrypted, {bcrypt}crypted …
4.3. Admin credentials
Either use system properties
pds.admin.userid pds.admin.apitoken
or env entries
PDS_ADMIN_USERID PDS_ADMIN_APITOKEN
to define admin credentisals. For apitoken please define encrypted password in spring boot
style - e.g. {noop}unencrypted, {bcrypt}crypted …
4.4. Workspace parent folder
With -Dpds.workspace.rootfolder or using environment variable PDS_WORKSPACE_ROOTFOLDER
workspace location can be defined
4.5. Server configuration file
The PDS reads a configuration JSON file on startup to configure the product delegation server and the provided products.
Location
Per default the file is pds-config.json in the folder were the PDS instance has been started.
|
With In our container images, the path is defined as |
Description
Here an example configuration with explanations:
{
"apiVersion" : "1.0",
"serverId" : "UNIQUE_SERVER_ID", (1)
"products" : [
{
"id" : "PRODUCT_1",(2)
"path" : "/srv/security/scanner1.sh",(3)
"scanType" : "codeScan",(4)
"description" : "codescanner script needs environment variable ENV_CODESCAN_LEVEL set containing 1,2,3",(5)
"parameters" : {(6)
"mandatory" : [(7)
{
"key" : "product1.qualititycheck.enabled",(8)
"description" : "when 'true' quality scan results are added as well"(9)
} ,
{
"key" : "product1.level",
"description" : "numeric, 1-gets all, 2-only critical,fatal and medium, 3- only critical and fatal"
}
],
"optional" : [(10)
{
"key" : "product1.add.tipoftheday",
"description" : "boolean as string, when 'true' we add always a tip of the day as info to results"
}, {
"key" : "pds.config.supported.datatypes", (11)
"default" : "source"
}
]
}
},
{
"id" : "PRODUCT_2",
"path" : "/srv/security/scanner2.sh",
"scanType" : "infraScan",
"parameters" : {
"mandatory" : [
{
"key" : "pds.config.supported.datatypes", (12)
"default" : "none"
}
]
},
"envWhitelist" : [ "SOME_SPECIAL_ENV_VARIABLE"] (13)
}
]
}| 1 | serverId is a unique identifier, which will be used determine a cluster /server. will be used inside logs and
also to share common database and divide different pds states etc.Allowed characters are [a-zA-Z0-9_]. Maximum length:30 (e.g FIND_SECURITY_BUGS_CLUSTER when providing a PDS server for find-security-bugs).
This is important ! Do NOT mix up different PDS clusters with same ID. |
| 2 | product id is a unique identifier, which will be used at job configuration time.
Defines what will be executed and is also the identifier for SERECO to check for dedicated
report handlingAllowed characters are [a-zA-Z0-9_]. Maximum length:30 |
| 3 | path defines what command / script will be executed. |
| 4 | scanType can be either
|
| 5 | description is a free text description |
| 6 | parameters area, here we can define optional and mandatory parameters. Those parameters will be available
in executed processes by environment variables.All other given job parameters will be IGNORED by server - reason: avoid unwanted changes on system environment variables from caller side |
| 7 | mandatory parameters - server will not accept jobs without these parameters |
| 8 | a key, will be transformed to ENV variable. In the given example product1.qualititycheck.enabled will be available in execution process
as environment variable PRODUCT1_QUALITYCHECK_ENABLED.
the value, will be set by SecHub job call and available in former described ENV entry at execution time.
SecHub will |
| 9 | a description of the key or the used default setup. This is optional and only for information/better understanding. |
| 10 | optional parameters |
| 11 | By defining supported data type source we ensure sources are downloaded from storage and automatically extracted.
If the extraction target folder is empty (e.g. filtering or no source available) the launcher script will NOT be called.Valid entries are source, binary, none or a combination of them as a comma separated list. When not defined as a parameter, the
PDS configuration default will be used. If available, the content of zip source files will be extracted into $PDS_JOB_EXTRACTED_SOURCES_FOLDER,
tar archive content containing binaries can be found at $PDS_JOB_EXTRACTED_BINARIES_FOLDER.The extraction will automatically filter and transform archive content as described at data structure definition. Also the environment variables $PDS_JOB_HAS_EXTRACTED_SOURCES and $PDS_JOB_HAS_EXTRACTED_BINARIES are automatically defined. |
| 12 | Using none will not try to download any ZIP or TAR from storage but does call the caller script even when no data is available. |
| 13 | An optional list of environment variable names which are additionally white listed from PDS script environment cleanup.
Those entries can also end with an asterisk, in this case every variable name starting with this entry will
be whitelisted (e.g. SPECIAL_VAR_* woud white list SPECIAL_VAR_CONNECTION_URL etc.)The PDS script cleanup process prevents inheritage of environment variables from PDS parent process. There are some also some default variable names which are automatically accepted (e.g. HOME, PATH, ..). |
4.6. Launcher scripts
4.6.1. Generated variables
| Variable name | Description | ||
|---|---|---|---|
PDS_JOB_WORKSPACE_LOCATION |
The workspace job root location |
||
PDS_JOB_RESULT_FILE |
The absolute path to the result file (this file contains security findings). |
||
PDS_JOB_UUID |
|||
PDS_JOB_EVENTS_FOLDER |
The absolute path to the user events folder. |
||
PDS_JOB_USER_MESSAGES_FOLDER |
The absolute path to the user messages folder. Every text file which is found inside this folder will be returned to user inside reports and status. There is a snippet for bash to create unique names. When a file starts with
The files must be simple text files and can contain multiple lines.
|
||
PDS_JOB_SOURCECODE_ZIP_FILE |
The absolute path to the uploaded "sourcecode.zip" file |
||
PDS_JOB_EXTRACTED_SOURCES_FOLDER |
When auto extracting is enabled (default) the uploaded source code is extracted to this folder |
||
PDS_JOB_EXTRACTED_BINARIES_FOLDER |
When auto extracting is enabled (default) the uploaded binaries are extracted to this folder |
||
PDS_JOB_EXTRACTED_ASSETS_FOLDER |
The absolute path to the extracted assets. |
||
PDS_SCAN_TARGET_URL |
Target URL for current scan (e.g webscan). Will not be set in all scan types. E.g. for a code scan this environemnt variable will not be available |
||
PDS_SCAN_CONFIGURATION |
Contains the SecHub configuration as JSON (but reduced to current scan type, so e.g. a web scan will have no code scan configuration data available) |
||
SECHUB_JOB_UUID |
The corresponding SecHub job UUID |
||
PDS_SCAN_TARGET_TYPE |
The network target type of the target URL. Possible values are: INTERNET, INTRANET. The network target type is injected by SecHub automatically. It does not need to be specified explicitly in the PDS Configuration file. |
4.6.2. Parameter variables
The parameters described inside the example configuration are defined at SecHub side in
Product executor configurations or automatically generated.
At execution time these parameters are sent by SecHub to PDS. Some are also available inside launcher scripts as environment variables.
It is possible define custom parameters for PDS solutions in the configuration file. Mandatory parts are always present, optional ones can be empty.
We have following standard parameters:
| Key | Description | Additional info |
|---|---|---|
sechub.productexecutor.pds.forbidden.targettype.internet |
When this key is set to true, then this PDS instance does not scan INTERNET! |
|
sechub.productexecutor.pds.forbidden.targettype.intranet |
When this key is set to true, then this PDS instance does not scan INTRANET! |
|
sechub.productexecutor.pds.timetowait.nextcheck.milliseconds |
When this is set, the value will be used to wait for next check on PDS server. If not, the default from PDS install set up is used instead. |
|
sechub.productexecutor.pds.timeout.minutes |
When this is set, the value will be used to wait before timeout happens when no communication with PDS server is possible. If not, the default from PDS install set up is used instead. |
|
sechub.productexecutor.pds.trustall.certificates |
When 'true' then all certificates are accepted. Do not use this in production! |
|
sechub.productexecutor.pds.adapter.resilience.retry.max |
Maximum amount of retries to handle resilience. When not defined or smaller than 0 the default will be: 3 |
|
sechub.productexecutor.pds.adapter.resilience.retry.wait.milliseconds |
Amount of milliseconds the PDS adapter shall wait before doing a next retry to handle resilience. When not defined or smaller than 1 the default will be: 10000 |
|
pds.config.productidentifier |
Contains the product identifier, so PDS knows which part is to call on it's side. |
|
pds.scan.target.type |
Contains the target type (depending on scan type) and will be just an additional information for PDS from SecHub. |
|
pds.config.use.sechub.storage |
When 'true' the SecHub storage will be reused by the PDS server. In this case SecHub will not upload job data to PDS. But it's crucial to have the same root storage setup on the PDS server side (e.g. same s3 bucket for S3 storage, or same NFS base for shared volumes). When not 'true' or not defined, PDS will use its own storage locations |
|
pds.config.use.sechub.mappings |
Contains a comma separated list of mappping ids. Each defined mapping will be fetched from SecHub DB as JSON and sent as job parameter with the mapping id as name to the PDS. |
|
pds.config.sechub.storage.path |
This contains the sechub storage location when sechub storage shall be used. So PDS knows location - in combination with sechub job UUID reuse is possible |
|
pds.config.filefilter.includes |
This contains a comma separated list of path patterns for file includes. These patterns can contain wildcards. Matching will be done case insensitive! Every file which is matched by one of the patterns will be included - except those which are explicitly excluded. When nothing is defined, then every content is accepted for include. For example: '*.go,*.html, test1.txt' would include every Go file, every HTML file and files named 'test1.txt'. |
|
pds.config.script.trustall.certificates.enabled |
When 'true' the PDS adapter script used by the job will have the information and can use this information when it comes to remote operations. |
|
pds.config.supported.datatypes |
Can be SOURCE, BINARY, NONE or a combination as a comma separated list. This data should normally not be defined via a default value of an optional PDS configuration parameter. |
|
pds.config.jobstorage.read.resilience.retries.max |
Defines the maximum amount of retries done when a job storage read access is failing |
|
pds.config.jobstorage.read.resilience.retry.wait.seconds |
Defines the time to wait in seconds before the next retry is done (when it comes to storage READ problems) |
|
pds.config.product.timeout.minutes |
Maximum allowed time in minutes, before a product will time out - this means that the launcher script is automatically canceled by PDS |
|
pds.config.filefilter.excludes |
This contains a comma separated list of path patterns for file excludes. These patterns can contain wildcards. Matching will be done case insensitive! When empty, then nothing will be excluded. The exclude operation will be done AFTER the include file filtering. For example: '*.go,*.html, test1.txt' would exclude every Go file, every HTML file and files named 'test1.txt'. |
|
pds.scan.target.url |
This contains the target URL for the current scan (i.e. webscan). Will not be set in all scan types. E.g. for a code scan this environment variable will not be available |
|
pds.debug.enabled |
When 'true', the PDS instance will show up some debug information on scan time. The output level of debugging information differs on PDS solutions/launcher scripts. |
|
pds.wrapper.remote.debugging.enabled |
Additional information will be always sent to launcher scripts. Interesting to debug wrapper applications remote. |
|
pds.add.scriptlog.to.pdslog.enabled |
When 'true', the PDS instance will add the complete log output from launcher script (and wrapper calls) to PDS log after the PDS launcher script has finished. |
|
pds.scan.configuration |
This contains the SecHub configuration as JSON object (but reduced to current scan type, so e.g. a web scan will have no code scan configuration data available |
|
pds.config.cancel.event.checkinterval.milliseconds |
This is the maximum time the launcher script process will be kept alive after a cancellation event is sent. This gives the launcher script process a chance to recognize the cancel event and do some final cancel parts and exit gracefully. |
|
pds.config.cancel.maximum.waittime.seconds |
The time in seconds PDS will check again if the launcher script process is alive or not when the process shall be canceled. When nothing defined, the default value is:0. If the value is 0 the process will be terminated without waiting. |
|
pds.mocking.disabled |
When 'true' any PDS adapter call will use real PDS adapter and not a mocked variant. |
|
pds.config.template.metadata.list |
Contains a list of template meta data entries (json). |
|
4.6.3. File locations
4.6.3.1. Upload
Content from uploaded user archives is extracted to:
PDS_JOB_EXTRACTED_SOURCES_FOLDER,
PDS_JOB_EXTRACTED_BINARIES_FOLDER
Content from uploaded asset files is extracted to:
PDS_JOB_EXTRACTED_ASSETS_FOLDER,
4.6.3.2. Output
Following files are reserved
-
system-err.log (created automatically by PDS)
$PDS_JOB_WORKSPACE_LOCATION/output/system-err.log -
system-out.log (created automatically by PDS)+ $PDS_JOB_WORKSPACE_LOCATION/output/system-out.log -
result.txt - this is the result file which must be created by the executed script
$PDS_JOB_WORKSPACE_LOCATION/output/result.txt. The path is represented by the variablePDS_JOB_RESULT_FILE
4.6.4. Events
Inside the folder defined in PDS_JOB_EVENTS_FOLDER the PDS writes events as json files inside.
Inside the event json file some standard information are always available (event type, creation time stamp ) and some dedicated, event specific details.
4.6.4.1. Cancel requested
When a file called cancel_requested.json is inside this folder, the PDS informs the script, that a cancel operation is ongoing.
Depending on the PDS setup, the PDS cancel service will wait a dedicated time for the script to finish. The time for the check operations and te
amount of seconds the PDS will wait for the script is contained in JSON.
If a PDS script (or a wrapper application executed by the script) has no special cleanup or follow up tasks on a cancel operation, the event can be ignored. But if there are operations to do (e.g. trigger/route the cancel to a 3rd party system) the script or the wrapper should check periodically if the event file is created. When the file exists, the necessary steps should be done by script (or wrapper application).
4.6.5. Product messages
We can write text files into the folder defined in PDS_JOB_USER_MESSAGES_FOLDER to send product messages back to users.
Info, error and warnings will be available inside the SecHub report and also inside the job status for the user.
4.6.5.1. Snippets
4.6.5.1.1. Bash messaging
Here a working solution for creating unique message files from bash scripts:
#!/bin/bash
# SPDX-License-Identifier: MIT
# You can paste this snippet inside your launcher script and use it to handle messages
function writeUniqueMessageFile(){
MSG_PREFIX=$1
MESSAGE=$2
MESSAGE_FILE_PATH="${PDS_JOB_USER_MESSAGES_FOLDER}/${MSG_PREFIX}_message_$(date +%Y-%m-%d_%H.%M.%S_%N).txt"
echo "$MESSAGE" > "$MESSAGE_FILE_PATH"
# additional echo to have the message also in output stream available:
echo "${MSG_PREFIX} message: $MESSAGE"
}
function infoMessage(){
writeUniqueMessageFile "INFO" "$1"
}
function warnMessage(){
writeUniqueMessageFile "WARNING" "$1"
}
function errorMessage(){
writeUniqueMessageFile "ERROR" "$1"
}Usage:
#!/bin/bash
# SPDX-License-Identifier: MIT
infoMessage "this is an info message"
warnMessage "this is a warning message"
errorMessage "this is an error message
with multiple lines...
"The former call did create following message files which contain the given text parts:
$job_folder_workspace/output/messages ├── ERROR_message_2022-06-24_17.56.52_822554054.txt ├── INFO_message_2022-06-24_17.56.52_818872869.txt └── WARNING_message_2022-06-24_17.56.52_820825342.txt
4.6.6. Storage configuration
In PDS we need to store job data (e.g. zipped source code).
At least one storage setup must be defined- otherwise PDS server will not start! You can either define a shared volume (normally a NFS) or a S3 storage.
Look at Storage configuration for configuration details.
4.6.7. Usage of SecHub storage
When using own storage for PDS servers, SecHub has to upload already pesisted job data (e.g. zipped sourcecode for SAST scannings) again to PDS storage-
This is a good separation between PDS instances and SecHub, but it does duplicate storage memory and also upload time which makes PDS job execution slower and can be a problem depending on the amount of jobs.
To increase this, SecHub administrators are able to edit the PDS executor configurations with an optional (but recommended)
job execution parameter pds.config.use.sechub.storage. When set to true, SecHub will not upload job data and PDS will reuse the
path locations from SecHub to obtain data to inspect.
See also PDS storage and sharing concepts.
|
If you have defined in your PDS product executor configuration to use SecHub job storage you YOU MUST use also SecHub same storage information. Otherwise it will not work and job data is not found! For an S3 storage this means, you will have to use exact same S3 bucket and provide PDS servers with correct S3 credential settings! |
4.7. Use cases
4.7.1. Overview about usecase groups
4.7.1.1. Anonymous
All these usecases handling anonymous access.
4.7.1.2. Job execution
Execution of PSD jobs
4.7.1.3. Monitoring
Monitoring usecases
4.7.1.4. Auto cleanup
Usecases about auto cleanup operations
4.7.2. PDS_UC_001-User creates job
A user creates a new PDS job
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
2 |
User creates job. If configuration is not valid an error will be thrown |
|
2 |
service call |
job will be created, serverId will be used to store new job |
4.7.3. PDS_UC_002-User uploads job data
A user uploads data for a job
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
2 |
User uploads a file to workspace of given job |
|
2 |
service call |
uploaded file is stored by storage service |
4.7.4. PDS_UC_003-User marks job ready to start
A user marks an existing PDS job as ready to start. Means all intermediate parts are done - e.g. uploads
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
User marks job as ready to start. |
4.7.5. PDS_UC_004-User cancels job
A user requests to cancel a PDS job
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
2 |
User cancels a job |
|
2 |
service call |
marks job status as cancel requested |
4.7.6. PDS_UC_005-User fetches job status
A user fetches current job status
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
2 |
User fetches status of a job. |
|
2 |
service call |
returns job status |
4.7.7. PDS_UC_006-User fetches job result
A user fetches job result
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
2 |
User wants to get result of a job |
|
2 |
service call |
Fetches job result from database. When job is not done, a NOT_ACCEPTABLE will be returned instead |
4.7.8. PDS_UC_007-Admin fetches monitoring status
An administrator fetches current state of cluster members,jobs running and also of execution service of dedicated memers. So is able to check queue fill state, jobs running etc.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
heartbeat update |
2 |
a scheduled heartbeat update is done by PDS server - will persist hearbeat information of server instance to database and also into logs |
|
2 |
db lookup |
3 |
service fetches all execution state |
|
3 |
rest call |
4 |
admin fetches monitoring status by REST API |
|
4 |
service call |
service fetches job state counts and gathers hearbeats of cluster members by serverId |
4.7.9. PDS_UC_008-Anonymous check if server is alive
Anonymous access to check if server is alive or not
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
anybody - even anonymous - checks server alive. |
4.7.10. PDS_UC_009-Admin fetches job result
Similar to the usecase when a user is fetching a job result. But will return current job result in any kind of state without throwning an error.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
2 |
an admin fetches result or failure text for job from db. |
|
2 |
service call |
Result data will be returned - will be empty if job is not done |
4.7.11. PDS_UC_010-Admin fetches server configuration
An administrator fetches the server configuration.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
an admin fetches server configuration of PDS server(s). |
4.7.12. PDS_UC_011-Admin fetches job output stream
An administrator can fetch the output stream text content via REST. Even when the PDS job is still running this is possible
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
2 |
an admin fetches output stream text. |
|
2 |
service call |
3 |
Output stream content of PDS job shall be returned. If the data is available in database and not outdated it will be returned directly. Otherwise job is marked for refresh and service will wait until stream data has been updated by executing machine. After succesful upate the new result will be returned. |
|
3 |
Request stream data refresh |
4 |
Updates the refresh request timestamp in database. This timestamp will be introspected while PDS job process execution - which will fetch and update stream content |
|
4 |
Update ouptut stream data |
Reads output stream data from workspace files and stores content inside database. Will also refresh update time stamp for caching mechanism. |
4.7.13. PDS_UC_012-Admin fetches job error stream
An administrator can fetch the output stream text content via REST. Even when the PDS job is still running this is possible
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
2 |
an admin fetches error stream text. |
|
2 |
service call |
3 |
Error stream content of PDS job shall be returned. If the data is available in database and not outdated it will be returned directly. Otherwise job is marked for refresh and service will wait until stream data has been updated by executing machine. After succesful upate the new result will be returned. |
|
3 |
Request stream data refresh |
4 |
Updates the refresh request timestamp in database. This timestamp will be introspected while PDS job process execution - which will fetch and update stream content |
|
4 |
Update error stream data |
Reads error stream data from workspace files and stores content inside database. Will also refresh update time stamp for caching mechanism. |
4.7.14. PDS_UC_013-Admin fetches auto cleanup configuration
An administrator can fetch the auto cleanup configuration via REST.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
Rest call |
2 |
Administrator fetches auto cleanup configuration |
|
2 |
Fetches auto cleanup configuration |
Fetches auto cleanup configuration from database |
4.7.15. PDS_UC_014-Admin updates auto cleanup configuration
An administrator can update the auto cleanup configuration via REST.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
Rest call |
2 |
Administrator changes auto cleanup configuration |
|
2 |
Updates auto cleanup configuration |
3, 4, 5 |
Updates auto cleanup configuration as JSON in database |
|
3 |
Calculate auto cleanup days |
After receiving the new cleanup configuration as JSON the cleanup days will be calculated and persisted as well |
4.7.16. PDS_UC_015-System executes auto cleanup
The PDS does execute an auto cleanup operation.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
Scheduling |
2 |
Checks for parts to auto clean. |
|
2 |
Delete old data |
deletes old PDS job data |
4.7.17. PDS_UC_016-User fetches job messages
A user fetches the messages a product has sent back to user at the end of a job.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
2 |
User wants to get messages of job |
|
2 |
service call |
Fetches job messages from database. When job is not already done a failure will be shown |
4.7.18. PDS_UC_017-Admin fetches job meta data
An administrator can fetch the meta data of a PDS jobvia REST. Even when the PDS job is still running this is possible.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
rest call |
2 |
an admin fetches meta data text or null. |
|
2 |
service call |
3 |
Meta data of PDS job shall be returned. If the data is available in database and not outdated it will be returned directly. Otherwise job is marked for refresh and service will wait until stream data has been updated by executing machine. After succesful upate the new result will be returned. |
|
3 |
Request meta data refresh |
4 |
Updates the refresh request timestamp in database. This timestamp will be introspected while PDS job process execution - which will fetch meta data content (if available) |
|
4 |
Update meta data |
Reads meta data from workspace file and stores content inside database if not null. Will also refresh update time stamp for caching mechanism. |
4.7.19. PDS_UC_018-System handles job cancellation requests
The PDS does handle job cancel requests. For every PDS job where a cancel request is active and the PDS instance does runs this job, the PDS will cancel it. When a orphaned cancel request is detected, this request will be handled as well.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
Scheduling |
2 |
Checks for PDS job cancel requests. |
|
2 |
service call |
3 |
cancels job if executed by this PDS and handles orphaned cancel requestes |
|
3 |
service call |
4 |
job execution will be canceled in queue |
|
4 |
process cancellation |
process created by job will be destroyed. If configured, a given time in seconds will be waited, to give the process the chance handle some cleanup and to end itself. |
4.7.20. PDS_UC_019-System handles SIGTERM
The PDS does listen to SIGTERM signal from OS and does necessary steps for next restart.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
Mark running jobs needing restart |
All running jobs in queue, which are not already done, will get the state READY_TO_RESTART |
4.7.21. PDS_UC_020-System executes job
The PDS does execute a PDS job.
Steps
| Nr | Title | Role(s) | Next | Description |
|---|---|---|---|---|
1 |
PDS trigger service fills queue |
2 |
Trigger service adds jobs to queue (when queue not full) |
|
2 |
Add Job to queue |
3 |
PDS job is added to queue |
|
3 |
PDS execution call |
3 |
Central point of PDS job execution. |
|
3 |
PDS execution call |
4 |
Central point of PDS job execution. |
|
4 |
PDS workspace preparation |
PDS job workspace is prepared here: Directories are created, files are downloaded and extracted etc. |
4.8. REST API
4.8.1. Big picture
4.8.2. Create JOB
See also Usecase PDS_UC_001-User creates job
https://${baseURL}/api/job/create [POST]Does contain configuration data for job execution as JSON in a very simple key value style:
{
"apiVersion" : "1.0",
"sechubJobUUID": "288607bf-ac81-4088-842c-005d5702a9e9", (1)
"productId": "THE_PRODUCT_IDENTIFIER", (2)
"parameters": [(3)
{
"key" : "sechub.test.key.1", (4)
"value" : "value1" (5)
},
{
"key" : "sechub.test.key.2",
"value" : "value2"
}
]
}| 1 | sechub job UUID - link back to sechub job. |
| 2 | product identifier - which product shall be used |
| 3 | parameter area - contains key value pairs to provide parameters at execution time |
| 4 | Represents the key, will be provided as argument ${sechub.test.key.1} but also as SECHUB_TEST_KEY_1 environment entry on process startup
so its up to the implementers if this is something that should not be shown in process tree…Only [a-z\.0-9] is allowed. . will be converted always to _ for the environment variables (spirng boot style) |
| 5 | Just the value. Must be always a string |
4.8.3. Upload data
https://${baseURL}/api/job/${jobUUID}/upload [POST]Uploaded data must be automatically destroyed after job has been done. This avoids file system freezes…
4.8.4. Mark JOB ready to start
https://${baseURL}/api/job/${jobUUID}/mark-ready-to-start [PUT]4.8.5. Cancel JOB
See also Usecase PDS_UC_004-User cancels job
https://${baseURL}/api/job/${jobUUID}/cancel [PUT]| This will stop the process hard! |
4.8.6. Fetch JOB status
https://${baseURL}/api/job/${jobUUID}/status [GET]4.8.7. Fetch JOB result
As user
See also Usecase PDS_UC_006-User fetches job result
https://${baseURL}/api/job/${jobUUID}/result [GET]As administrator
See also Usecase PDS_UC_009-Admin fetches job result
https://${baseURL}api/admin/job/{jobUUID}/result [GET]4.8.8. Get monitoring status
https://${baseURL}/api/admin/monitoring/status [GET]Here an example output:
{
"serverId": "serverid1",
"jobs": {
"CREATED": 1,
"QUEUED": 1,
"READY_TO_START": 1,
"RUNNING": 1,
"DONE": 1
},
"members": [
{
"hostname": "hostname1",
"ip": "192.168.178.23",
"heartBeatTimestamp": "2020-07-08T17:22:36.295",
"executionState": {
"queueMax": 50,
"jobsInQueue": 0,
"entries": [
]
}
},
{
"hostname": "hostname2",
"ip": "192.168.178.24",
"heartBeatTimestamp": "2020-07-08T17:22:36.295",
"executionState": {
"queueMax": 50,
"jobsInQueue": 1,
"entries": [
{
"jobUUID" : "c3917a46-456f-4006-888a-08f74cc26a7a",
"done": false,
"canceled": false,
"created": "2020-07-08T17:22:33.132",
"started": "2020-07-08T17:22:36.295",
"state": "RUNNING"
}
]
}
}
]
}4.8.9. Check server alive
https://${baseURL}/api/anonymous/check/alive [GET,HEAD]4.8.10. Fetch server configuration
https://${baseURL}/api/admin/config/server [GET]Here an example output:
{
"apiVersion" : "1.0",
"serverId" : "example-server",
"products" : [ {
"id" : "PDS_TESTPRODUCT_ID",
"scanType" : "codeScan",
"path" : "./testproduct-codescan.sh",
"envWhitelist" : [ "SPECIAL_ENV_NAME" ],
"description" : "A description of the product",
"parameters" : {
"mandatory" : [ {
"key" : "testproduct.mandatory_parameter",
"description" : "A description for this mandatory parameter"
} ]
}
} ]
}| You find more details about PDS server configuration here |
4.8.11. Fetch job output stream
https://${baseURL}api/admin/job/{jobUUID}/stream/output [GET]4.8.12. Fetch job error stream
https://${baseURL}api/admin/job/{jobUUID}/stream/error [GET]4.8.13. Fetch auto cleanup configuration
https://${baseURL}/api/admin/config/autoclean [GET]Example result:
{
"cleanupTime" : {
"unit" : "DAY",
"amount" : 2
},
"version" : "1.0"
}| The concept for auto cleanup is defined here. |
4.8.14. Update auto cleanup configuration
https://${baseURL}/api/admin/config/autoclean [PUT]Example body data:
{
"cleanupTime" : {
"unit" : "DAY", (1)
"amount" : 3 (2)
},
"version" : "1.0"
}| 1 | Defines the used time unit. Can be a either MILLISECOND, SECOND, MINUTE, HOUR or DAY |
| 2 | Amount of time (for given unit) - in the example above we have defined 3 days |
| The concept for auto cleanup is defined here. |
4.8.15. Fetch job messages
https://${baseURL}/api/job/{jobUUID}/messages [GET]Example result:
{
"secHubMessages" : [ {
"type" : "INFO",
"text" : "some information - e.g. from a PDS test product launcher script"
} ],
"type" : "sechubMessagesList"
}4.8.16. Fetch job meta data
| The concept of PDS job meta data handling is described here . |
https://${baseURL}/api/admin/job/{jobUUID}/metadata [GET]Example result:
{
"metaData" : {
"key1" : "value1",
"key2" : "value2"
}
}